
Welcome to chapter 10 AP Stats Review, an immersive journey into the fascinating world of data analysis. In this chapter, we’ll explore descriptive statistics, probability distributions, hypothesis testing, confidence intervals, and regression analysis. Get ready to delve into the art of making sense of data!
Descriptive statistics provide the foundation for understanding data, helping us summarize and describe its key characteristics. We’ll dive into measures of central tendency (mean, median, mode) and variability (range, variance, standard deviation), unlocking their power in data analysis.
Introduction
Welcome to the AP Statistics Chapter 10 review! This review is designed to help you solidify your understanding of the key concepts covered in the chapter, including sampling distributions, confidence intervals, and hypothesis testing.
By the end of this review, you should be able to:
- Understand the concept of a sampling distribution and how it relates to the population distribution.
- Construct and interpret confidence intervals for population parameters.
- Conduct hypothesis tests to determine if there is a significant difference between two populations.
Sampling Distributions
A sampling distribution is a probability distribution of a statistic calculated from all possible samples of a given size from a population. The sampling distribution of the sample mean is approximately normal, regardless of the shape of the population distribution, if the sample size is large enough (n > 30).
Descriptive Statistics: Chapter 10 Ap Stats Review
Descriptive statistics provide a concise summary of data, making it easier to understand and draw meaningful conclusions. They help us describe the central tendencies and variability within a dataset.
Measures of Central Tendency
Measures of central tendency provide a single value that represents the “typical” value in a dataset. They include:
- Mean:The average of all values in a dataset.
- Median:The middle value in a dataset when arranged in ascending or descending order.
- Mode:The value that occurs most frequently in a dataset.
Measures of Variability
Measures of variability describe how spread out the data is. They include:
- Range:The difference between the largest and smallest values in a dataset.
- Variance:The average of the squared differences between each data point and the mean.
- Standard Deviation:The square root of the variance, which represents the average distance of data points from the mean.
Understanding descriptive statistics is crucial for data analysis, as they provide valuable insights into the distribution and characteristics of a dataset.
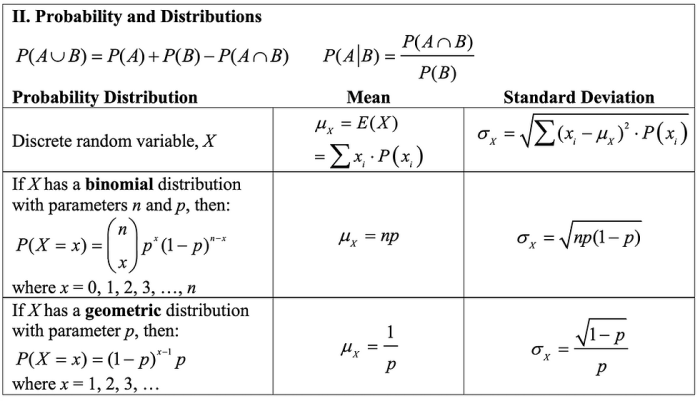
Probability Distributions

Probability distributions are mathematical functions that describe the likelihood of different outcomes in a random experiment. They play a crucial role in statistical modeling by providing a framework for predicting and analyzing the behavior of random variables.
Common probability distributions include the binomial distribution, which models the number of successes in a sequence of independent experiments, the normal distribution, which describes continuous data with a bell-shaped curve, and the t-distribution, which is used for estimating population means when the sample size is small.
Sampling Distributions
Sampling distributions are probability distributions of sample statistics, such as the mean or proportion, calculated from repeated random samples of the same size from a population. They are important because they allow us to make inferences about the population based on sample data.
The relationship between probability distributions and sampling distributions is that the sampling distribution of a statistic is determined by the probability distribution of the underlying random variable.
Hypothesis Testing

Hypothesis testing is a statistical method used to evaluate claims about a population. It involves formulating hypotheses, collecting data, and making a decision based on the evidence.
Null and Alternative Hypotheses, Chapter 10 ap stats review
The null hypothesis (H 0) represents the claim being tested, while the alternative hypothesis (H 1) represents the alternative claim. The null hypothesis is typically set as the default or current belief, while the alternative hypothesis is the claim being investigated.
Steps in Hypothesis Testing
- Formulate hypotheses: State the null and alternative hypotheses.
- Collect data: Obtain a sample from the population.
- Calculate test statistic: Use the sample data to calculate a test statistic that measures the difference between the observed and expected results.
- Make a decision: Compare the test statistic to a critical value or p-value to determine if the null hypothesis should be rejected.
Type I and Type II Errors
Type I error (false positive) occurs when the null hypothesis is rejected when it is actually true. Type II error (false negative) occurs when the null hypothesis is not rejected when it is actually false.
The probability of making a Type I error is controlled by the significance level (α), while the probability of making a Type II error is controlled by the power of the test.
Chapter 10 of AP Statistics Review covers a wide range of topics, from probability distributions to hypothesis testing. But before you dive into the nitty-gritty, it’s important to make sure you have the basics down. That’s where the alpha sigma phi pledge pin comes in.
This handy little tool can help you quickly review key concepts and formulas. Once you’ve got the basics down, you’ll be well on your way to mastering Chapter 10 of AP Statistics Review.
Confidence Intervals

In statistical inference, confidence intervals are an essential tool for making estimates about population parameters based on sample data. They provide a range of plausible values within which the true population parameter is likely to lie.
Confidence intervals are constructed using a specific level of confidence, typically 95% or 99%. The confidence level represents the probability that the true population parameter falls within the calculated confidence interval.
Methods for Constructing Confidence Intervals
There are various methods for constructing confidence intervals, depending on the type of data and the population parameter being estimated.
- For means:t-distribution or z-distribution
- For proportions:normal distribution or binomial distribution
- For variances:chi-square distribution
Each method involves using the sample data to calculate a point estimate of the population parameter and then adding and subtracting a margin of error to create the confidence interval.
Interpretation and Limitations of Confidence Intervals
Confidence intervals provide valuable information about the likely range of population parameters. However, it’s important to interpret them correctly and be aware of their limitations.
- Interpretation:Confidence intervals indicate the range of values within which the true population parameter is likely to lie, with a specified level of confidence.
- Limitations:Confidence intervals are not exact predictions but rather estimates based on sample data. They can be affected by sampling error and the size of the sample.
Regression Analysis
Regression analysis is a statistical technique used to understand the relationship between a dependent variable and one or more independent variables. It allows us to predict the outcome of the dependent variable based on the values of the independent variables.Regression
analysis is widely used in various fields, such as economics, finance, healthcare, and marketing, to make predictions, identify trends, and evaluate the impact of different factors on a particular outcome.
Types of Regression Models
There are two main types of regression models: linear and multiple.
- Linear regressionmodels the relationship between a single dependent variable and a single independent variable.
- Multiple regressionmodels the relationship between a single dependent variable and two or more independent variables.
Assumptions of Regression Models
Regression models rely on certain assumptions to ensure their validity. These assumptions include:
- Linearity:The relationship between the dependent and independent variables is linear.
- Independence:The observations in the dataset are independent of each other.
- Homoscedasticity:The variance of the residuals (errors) is constant across all values of the independent variables.
- Normality:The residuals are normally distributed.
Interpretation of Regression Coefficients
The regression coefficients represent the change in the dependent variable for a one-unit change in the corresponding independent variable, holding all other variables constant. A positive coefficient indicates a positive relationship, while a negative coefficient indicates a negative relationship.The intercept of the regression line represents the value of the dependent variable when all independent variables are equal to zero.
Goodness-of-Fit Measures
Goodness-of-fit measures evaluate how well the regression model fits the data. Common measures include:
- R-squared:Represents the proportion of variance in the dependent variable that is explained by the independent variables.
- Adjusted R-squared:Adjusts R-squared for the number of independent variables in the model.
- Mean squared error (MSE):Measures the average squared difference between the predicted values and the actual values.
Essential Questionnaire
What is the purpose of descriptive statistics?
Descriptive statistics help us summarize and describe data, providing a clear understanding of its central tendencies and variability.
How do I calculate the mean of a dataset?
To calculate the mean, add up all the values in the dataset and divide the sum by the total number of values.
What is the difference between a hypothesis test and a confidence interval?
A hypothesis test helps us determine if there is a significant difference between two groups, while a confidence interval provides a range of possible values for a population parameter.
